Smart Contracts Explained: A Comprehensive Guide for Data Analysts
When I started querying blockchain data, I knew SQL. I didn't know why some things showed up in tables and others didn't. Why could I find every token transfer but not historical balances? Why did some contracts have clean decoded tables while others required parsing raw hex?
You see, I thought I could query a smart contract like a database. Pull up a wallet, check its balance at any point in time, done. But I quickly found out that is not how it works. With Flipside and Dune feeling really daunting to use at inception, I had to learn that the gap was in my understanding of smart contract fundamentals.
Once I understood how contracts actually work, what creates on-chain records versus what doesn't, everything clicked. This is what I wish someone had told me earlier when it came to data. Okay, here’s what I mean:
A smart contract is a program on a blockchain. Unlike server software, it runs on thousands of computers simultaneously and can't be modified once deployed. Think of it as a vending machine:
The machine is the contract
The buttons are functions
The receipt is an event
The product is the state change (tokens moving, balances updating)
The receipt is what we query as data analysts and engineers. However, the machine's internal state is harder to access directly.
My first real task was simple
Find the balance of a wallet at a specific block height from six months ago. I wrote what I thought was a straightforward query, looking for some kind of balance history table. Nothing came back.
I spent an hour thinking my SQL was wrong before I realized the data I was looking for did not exist. Not because it was deleted or hidden, but because it was never recorded in the first place.
Smart contracts have a function called balanceOf() that returns the current balance of any address. But here is the thing: calling that function does not create a transaction. It does not write anything to the blockchain. It just reads the current state and returns it. There is no log, no receipt, no record that the call ever happened.
That was my first real lesson. Read functions are invisible. They answer questions in the moment but leave no trace for analysts to find later.
Why Some Data Exists, and Some Doesn't
This confused me initially. The answer lies in understanding functions.
Write functions that modify the blockchain. When called, they create a transaction with a hash, block number, timestamp, and gas cost. This is queryable data.
Read functions only retrieve the current state. They're free to call, create no transaction, and leave no on-chain trace.
This is why you can't directly query "what was wallet X's balance at block Y" in Dune. That's a read function result. But you can reconstruct it by aggregating Transfer events; every balance change leaves a receipt. That’s the trick.
To understand this better, think of it like a Vending Machine
Someone gave me an analogy that made everything fall into place.
Think of a smart contract like a vending machine. You walk up, put in money, press a button, and get a snack. The machine has rules built into it. If you pay the right amount and press a valid button, you get your product. No negotiation, no human intervention.
Now think about what gets recorded:
Pressing a button that dispenses a snack? That is a write function. Something changed. The machine's inventory went down, your money went in, and there is a receipt.
Looking at the display to see what is available? That is a read function. You got information, but nothing changed. No receipt.
As a data analyst, you only have access to the receipts. This reframed everything for me. I stopped looking for data that was never written and started focusing on what was: the events.
Events: The Analyst's Primary Data Source
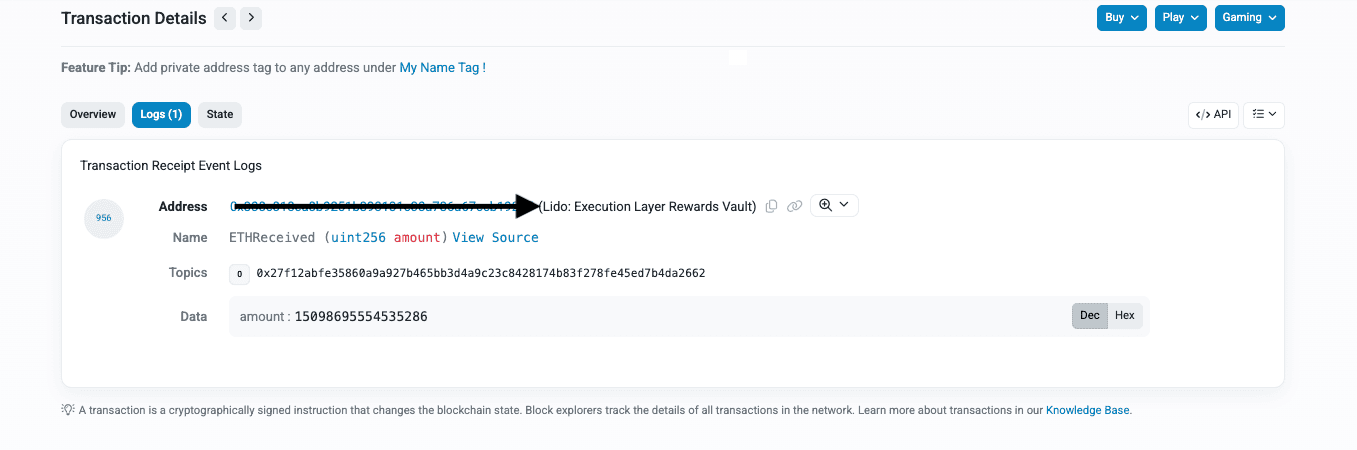
Events are the primary data source for blockchain analytics. They are structured logs that contracts emit when something happens.
The standard ERC-20 Transfer event looks like this:
Plain Text
Transfer(address indexed from, address indexed to, uint256 value)
Every time tokens move, this event fires. It records who sent, who received, and how much. This is what I query in Dune.
The word "indexed" matters. Indexed parameters become "topics" that I can filter on efficiently. The Transfer event has from and to indexed, which means I can quickly find all transfers to or from a specific address.
In Ethereum logs:
topic0is the event signature (identifies which event type)topic1is the first indexed parameter (from)topic2is the second indexed parameter (to)datacontains everything else (value)
When I write a query to find all transfers to a specific wallet, I am filtering on topic2.
Function Selectors and Event Signatures
Every function and event has a unique identifier. These are hashes that look like 0xa9059cbb for functions or 0xddf252ad... for events. For the transfer(address,uint256) function:
Take the function signature:
transfer(address,uint256)Hash it with
keccak256Take the first 4 bytes:
0xa9059cbb
This selector is included in every transaction that calls this function. So if I want to find all transfer calls (not just the events, but the actual function calls), I can filter transactions by this selector.
For events, it is similar but uses the full 32-byte hash as topic0.
[Updating what I do now]: Now, I do not calculate these by hand. Tools like Herd.eco show them for every function and event, which saves time. Previously, when this article was written, you’d need to do it manually.
Another Thing I Learned About Addresses
Ethereum addresses are case-insensitive, but SQL comparisons might not be. I ran into issues early on where queries returned nothing because of case mismatches.
Now I always normalize addresses to lowercase or use the native bytea format in DuneSQL:
-- This works in DuneSQL WHERE contract_address = 0x7e2ac793f3E692f388e66c7DC28F739d13B0B71A
Another thing: addresses in topics are padded to 32 bytes. So a 20-byte address gets 12 bytes of zeros in front. This matters when working with raw logs. I assumed that a contract address always meant the same code. That is not true for upgradeable contracts.
Many contracts use a proxy pattern. There are two contracts:
The proxy holds the state (balances, etc.) and has the address everyone uses
The implementation holds the logic and can be swapped out
When the team upgrades the contract, they deploy new logic and point the proxy to it. The address stays the same, but the code changes.
For data analysis, this means historical data might have been generated by different code than what exists today. If I am analyzing a contract that has been upgraded, I need to check when the upgrades happened and whether they changed anything relevant to my analysis.
The Upgraded event tells me when implementation changes occurred. Now, when I use Herd.eco to analyze a contract, I see emission counts for each event. Some show zero. At first, I thought this meant the event was not implemented. That is wrong. It means the event exists in the code but has never been triggered.
The zero-emission events are still important. They tell me what the contract can do, even if it has not done it yet.
For risk analysis, knowing that a contract has blacklisting capability matters even if no one has been blacklisted.
How I Approach a New Contract Now
When I need to analyze a new contract, here is my process:
Step 1: Identify the basics
Is it upgradeable? (Check for proxy patterns)
What standard does it follow? (ERC-20, ERC-721, custom)
When was it deployed?
Step 2: Map the functions
What write functions exist?
Which ones have actually been called?
What access control is in place?
Step 3: Map the events
What events does it emit?
Which ones have emissions?
What data do they contain?
Step 4: Build queries from events
Start with the high-emission events
Reconstruct state from event history
Add filters for specific analysis
Tools like Herd.eco make steps 2 and 3 fast. I can see all functions and events with their call counts and signatures in one view.
Reconstructing Historical State
Since I cannot query historical read function results directly, I reconstruct the state from events.
For token balances:
WITH transfers AS ( SELECT "to" as address, CAST(value AS DECIMAL(38,0)) as amount FROM erc20_ethereum.evt_Transfer WHERE contract_address = 0x7e2ac793f3E692f388e66c7DC28F739d13B0B71A UNION ALL SELECT "from" as address, -CAST(value AS DECIMAL(38,0)) as amount FROM erc20_ethereum.evt_Transfer WHERE contract_address = 0x7e2ac793f3E692f388e66c7DC28F739d13B0B71A ) SELECT address, SUM(amount) / 1e18 as balance FROM transfers WHERE address != 0x0000000000000000000000000000000000000000 GROUP BY address HAVING SUM(amount) > 0 ORDER BY balance DESC
This gives me current balances. To get historical balances at a specific block, I add a block number filter:
Mints and Burns Are Just Special Transfers
This was a small realization, but it simplified my thinking.
A mint is a Transfer event where the from address is the zero address (0x000...000). Tokens are created from nothing.
A burn is a Transfer event where the to address is the zero address. Tokens are destroyed.
So I do not need separate mint and burn queries. I just filtered Transfer events:
-- MintsWHERE "from" = 0x0000000000000000000000000000000000000000 -- Burns WHERE "to" = 0x0000000000000000000000000000000000000000
Some contracts emit custom TokensMinted or TokensBurned events with additional data, but the Transfer event is always there.
What I Wish I Knew Earlier
Read functions leave no trace. Do not look for data that does not exist.
Events are the data source. Learn to work with them.
Indexed parameters are filterable. Check which parameters are indexed before writing queries.
Upgradeable contracts change over time. Check for proxy patterns and upgrade history.
Zero emissions means unused, not missing. The capability exists even if it has not been used.
Addresses need normalization. Be defensive about the case and formatting.
Tools exist to speed this up. Herd.eco, Etherscan, and others show contract structure without reading code.
Historical state is reconstructed, not queried. Build it from events.
Resources That Helped Me
Dune Analytics Documentation - Query patterns and table schemas
Etherscan - Contract verification and basic analysis
Herd.eco - Function and event mapping with call counts
OpenZeppelin Docs - Standard contract patterns
EIP-20 - The ERC-20 token standard